Place and Colour
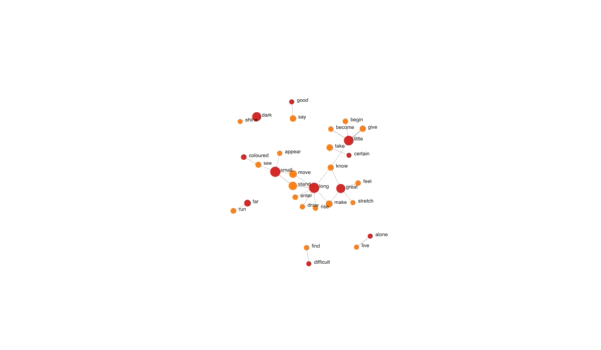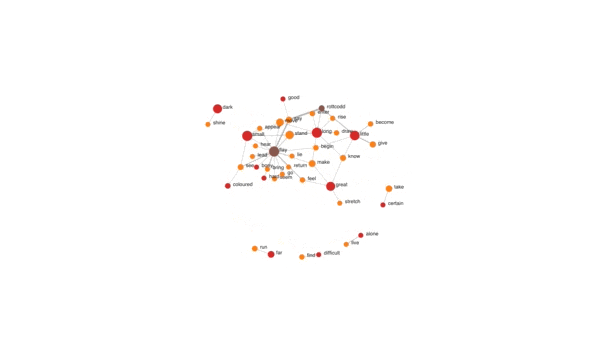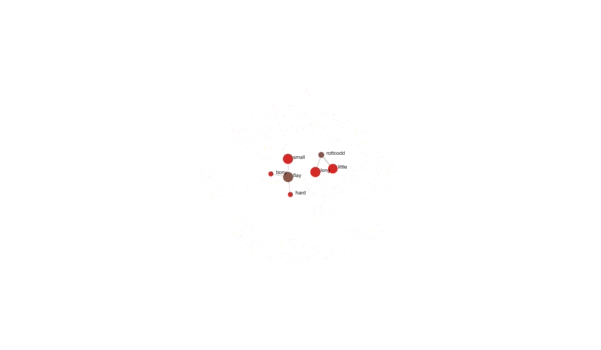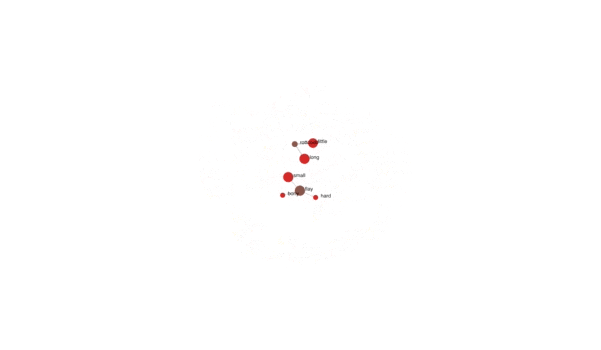
Place and Colour: Term Explorer tool showing links between words categorised by part of speech. Video and application by William Ward.
Contributors: William Ward; Stanislav Roudavski; Greer Gardner; Mark Burry; Gini Lee; Jeff Malpas; Mark Taylor.
Living exhibition available on the Deep Design Lab website and GitHub.
This project grew from work by William Ward and Stanislav Roudavski for the Place and Parametricism grant. The grant investigated literary places using Mervyn Peake's Gormenghast trilogy. One aim was to translate language describing places into design parameters. We focused on colour words and place terms. Colour terms are easy to identify, diverse, and translate to visual representations.
Text analysis can identify parts of speech (e.g., nouns, adjectives, etc.), predict named locations and entities (e.g., Gormenghast Castle, Titus), and quantify word relatedness (e.g., black commonly appears with castle). Experimentation revealed the challenges of defining, quantifying and relating specific 'places' and phenomena.
Metrics based on large datasets (e.g., Google Ngrams) provide general answers:1 based on probability, a castle has ramparts; a castle is gray; gray is rgb(128,128,128); a gray castle looks like this:

Artificial intelligence can in theory generate an 'average' representation of a place. Current methods cannot render three-dimensional environments with parametric atmospheres, temporality, geometries, and spatial relationships. Such analyses flatten the diversity that defines 'place'.
Constructing a meaningful representation of a place from descriptions requires knowledge of a text's author, cultural context, characters, environments, and events. A reader's subjectivity–their life experiences, culture, capabilities, biases, knowledge–influences place construction. Randomisation can approximate variations, but parametricising these factors and their influence exceeds theories of place and technological capabilities.
These limitations informed a new research direction. Automating representation requires understanding. To understand how place is constructed, one must understand subjectivity and develop empathy. This demands tools that are non-hierarchical, omnidirectional, transparent, ambiguous, extendable, and malleable. We propose a virtual exhibit of concepts with a user-experience fulfilling these values.
We suggest that an observer's perceptions define their sense of place. Species share perceptual abilities, but their capabilities vary. Eight perceptual phenomena (non-exhaustive) construct 'place': colour, communication, culture, design, patterns, place, senses, and subjectivity. These categories overlap and contradict one another, reflecting limited knowledge and communication across disciplines. We focus on humans and nonhumans because differences in perception are more significant and well-documented than those among humans. Intentional design requires negotiation of interspecies differences across all phenomena and capabilities.
Language is a key barrier to interspecies communication. Knowledge of nonhuman subjectivities, capabilities, and needs support informed design decisions, but exists across multiple disciplines. Technical language and disciplinary blindness limit accessibility to non-experts. Uniting information facilitates exploration, identification of commonalities, and synthesis. Because knowledge is incomplete, unrelated, or incompatible, these links must be porous and indiscriminate towards discipline.
We conceptualised this exhibit as a design experiment with four desired qualities:
- Complex: Express complex relationships between concepts from physics, biology, culture, and design.
- Non-deterministic: Present this information in a form that overcomes the constraints of journals and books, e.g.: linearity, unidirectionality, completeness.
- Alive: Exhibit this information using a format that encourages asynchronous curiosity, engagement and iteration. Avoid technical, complex and/or proprietary formats that complicate modification.
- Open: Reduce barriers to participation and make decision-making transparent.
We implement these methods using Dendron, an open-source application for personal note-taking. Dendron provides features that satisfy our experiment aims:
- bidirectional linking (non-deterministic, complex)
- flexible hierarchies (complex, alive)
- web publishing (alive, open)
- source control using git and GitHub (alive, open)
- written using Markdown (alive, open)
- open-source (alive, open)
Four entities facilitate this user-experience within our Dendron wiki:
- Notes house information attributed to its source.
- Links allow non-linear exploration across topics and disciplines.
- Experiments visualise dynamics within phenomena, for example: the anthropocentrism of colour language, the inexactness of place and colour words, and the challenges of quantifying descriptive texts.
- Stories organise content into narratives that focus on how agents experience phenomena, for example: the environmental factors that led a bird species to evolve colour perception, how this subjective experience of colour differs from humans, and the consequences of ignorance of difference.
Outlining a novel exhibition model is a secondary aim of the project.
Standard exhibitions are unidirectional, linear and metaphorical. Commonly, an artwork transmits a symbolic message to an audience, a process susceptible to misinterpretation, selection bias, criticism, and ineffectiveness. Participatory artworks establish new processes and relationships that produce real impacts, but lack repeatability. A niche exists for art forms that function autonomously across many locations, contexts and timelines.
Images
Image title: Description. Medium by author/by the authors.
Video(s)
Title: Description. Medium by author/by the authors.
Links
Related Projects
- Place and Parametricism (2019)
- Place and Colour (2019)
- Invisible Places (2019)
- Sensing Place (2019)
- Trees as Place (2019)
Acknowledgements
Footnotes
For example, the Wall Street Journal (WSJ) dataset of the Penn Treebank is standard for part-of-speech tagging. The dataset contains 1 million words from 2,499 WSJ articles from 1989, tagged manually by researchers. This set is reliable for large and small-scale analyses, because sentence position determines part-of-speech more than meaning. Dataset bias complicates analysis of small corpora with unusual language. Statistical analysis of small, unique corpora also produces unreliable results. In general, universal tasks (part-of-speech tagging, word concordance, topic modelling, named entity recognition) work on texts of any size; language-sensitive tasks (sentiment analysis, categorisation using lexicons, word disambiguation) are less reliable for small corpora.˄
Backlinks